بهینه سازی عملکرد در Power BI
در زمینه بهینه سازی عملکرد Power BI نکات مهمی باید در نظر گرفته شود که مهمترین آن ها مصرف CPU و RAM است. یکی از پایه ای ترین و در عین حال مهمترین ملاحظات کاهش مصرف RAM است. به صورت پیش فرض تمام جداول و کوئری های موجود در Query Editor در RAM بارگذاری می شوند. اگر ملاحظات مربوط به بهینه سازی در Power BI رعایت نشوند، با چالش های متعددی روبرو خواهیم بود مخصوصا وقتی که مدل ما حجیم شود.
ساز و کار بارگذاری در Power Query
به طور پیش فرض تمام جداول و Query ها در مدل ما بارگذاری می شوند. این رفتار پیش فرض به شرطی که ما با یک انبار داده مناسب و با مدل ستاره ای روبرو باشیم، بسیار مطلوب است چرا که نیازی به تغییر در ساختار داده ها، جداول و کوئری ها نداریم، اما وقتی به پایگاه داده تراکنشی، صفحات وب، صفحات گسترده و هر منبع داده غیر ستاره ای متصل شویم با چالش های بسیاری روبرو خواهیم بود.
به طور معمول وقتی به منبع داده متصل می شویم، نیاز به اعمال تغییرات بر روی داده ها، ستون ها، ردیف ها، استفاده از Merge، بهره گیری از Append و دیگر اعمال به منظور دستیابی به داده مناسب برای گزارش گیری خواهیم داشت. در نهایت ممکن است ما 5 جدول نهایی از ده ها جدول و کوئری فراخوانی شده در Query Editor، استخراج کنیم.
به طور پیش فرض هنگامی که اعمال پاکسازی داده را به اتمام می رسانید و گزینه Close and Apply را انتخاب می کنید، تمام جداول و کوئری ها، فارغ از این که به آن ها نیاز دارید یا خیر در مدل نهایی بارگذاری می شود.
تغییرات و تبدیلات مورد نظر قبل از بارگذاری در RAM صورت می پذیرد، به همین دلیل گفته می شود تغییرات و دستکاری ها داده در M، بسیار بهینه تر از انجام همین اعمال در DAX است. باید به این نکته توجه داشت که وقتی جداول در RAM بارگذاری شد، حتی با مخفی کردن آن جدول در محیط گزارش، جدول مربوطه مصرف RAM را خواهد داشت.
هر جدولی که در مدل بارگذاری می شود مصرف RAM خواهد داشت و RAM مهمترین دارایی ما است و استفاده کمتر از این دارایی باعث بهینه شدن عملکرد می شود. وقتی Close and Apply را انتخاب کردید، جدول در RAM بارگذاری می شود. پس Hide کردن آن فقط جدول را از دید کاربر مخفی می کند و کمکی به بهینه سازی مدل نخواهد کرد. بهترین رویکرد این است که اگر به جدولی نیاز ندارید قبل از Close and Apply فکری به حال آن بکنید و از بارگذاری آن در RAM جلوگیری کنید.
وقتی که در Power BI بر روی Refresh کلیک می کنیم یا برای Refresh زمان بندی اتوماتیک در نظر می گیریم، تمام جداول و کوئری ها چه در حالت Enable load باشند چه در حالت Disable Load، به روز رسانی می شوند. اما اگر برای جداولی که به عنوان جداول میانی و کمکی برای ایجاد جداول اصلی استفاده نموده اید گزینه Disable Load را استفاده کنید، با هر بار به روز رسانی داده های آن ها به روز رسانی می شود اما در RAM بارگذاری نمی شود. در واقع این جداول نقش خود را به عنوان جداول کمکی و میانی ایفا می کنند، اما در RAM بارگذاری نمی شوند.
شاید به نظر شما رعایت این نکته ساده، مهم به نظر نرسد، اما وقتی مدل شما بزرگ و بزرگ تر می شودتوجه به همین نکات ساده باعث افزایش عملکرد شما خواهد شد.
بررسی یک سناریو
قصد داریم محتویات یک فولدر را که در تصویر مشاهده می کنید، بارگذاری کنیم. محتویات فولدر شامل دو نوع فایل است که حاوی اطلاعات دانش آموزان و واحد ها می باشد. هر دو نوع فایل ها csv هستند ولی در ساختار های متفاوتی ذخیره شده اند. علاوه بر این ها فایل های دیگری نیز در این فولدر وجود دارند که ما قصد پردازش آن ها را نداریم.
هدف نهایی بارگذاری داده های دانش آموزان و دروس در دو جدول جداگانه در مدل است.
خواندن اطلاعات فولدر
یک فایل Power BI باز می کنیم. از طریق Get Data، گزینه Folder را انتخاب می کنیم.

مسیر فولدر را در باکس مشخص شده در تصویر، وارد میکنیم.
 گزینه Edit Query را انتخاب می کنیم. همان طور که در تصویر قابل مشاهده است چندین نوع فایل در فولدر وجود داشته که برخی از آن ها csv برخی txt یا html و docx هستند. اما فایل های مورد نظر ما فایل های دانش آموزان و دروس که با پسوند csv. هستند.
گزینه Edit Query را انتخاب می کنیم. همان طور که در تصویر قابل مشاهده است چندین نوع فایل در فولدر وجود داشته که برخی از آن ها csv برخی txt یا html و docx هستند. اما فایل های مورد نظر ما فایل های دانش آموزان و دروس که با پسوند csv. هستند.
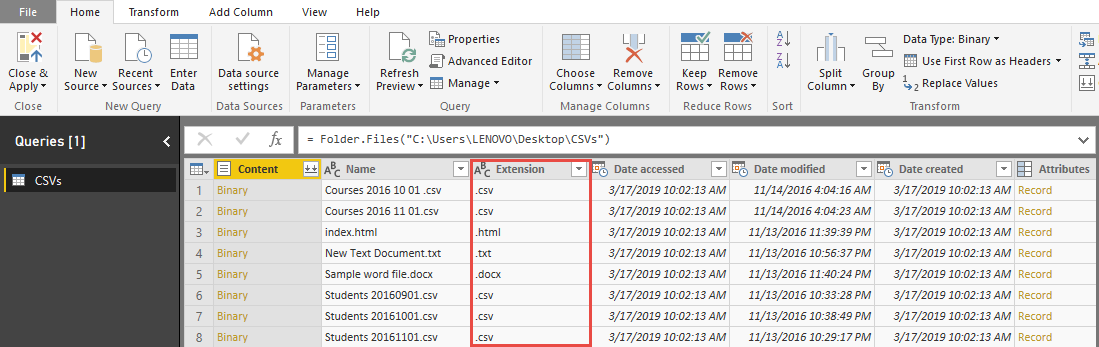
ابتدا فایل های csv. را که حاوی داده های دانش آموزان و دروس هستند را فیلتر می کنیم.
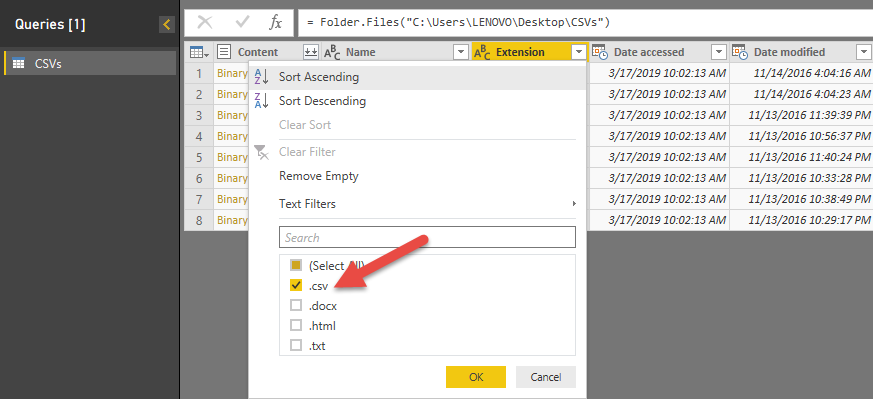
نتیجه مطابق تصویر زیر خواهد بود که طی آن تنها 2 فایل حاوی اطلاعات دروس و 3 فایل حاوی اطلاعات دانش آموزان باقی مانده است. این فایل ها ساختار متفاوتی دارند.

برای اینکه بتوانیم این فایل ها را به دو زیر مجموعه دانش آموزان و دروس تقسیم بندی کنیم می توانیم بار دیگر عمل واکشی فولدر را تکرار کنیم. اما راهکار بهتر این است که از عمل reference استفاده کنیم. بر روی کوئری کلیک راست کرده و گزینه Reference را انتخاب می کنیم.
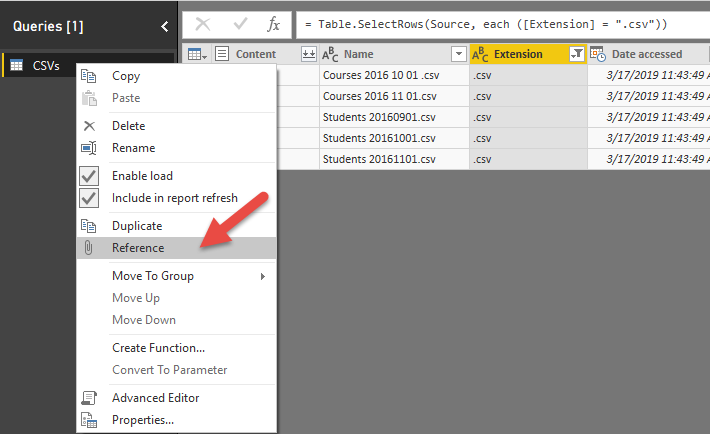
حال همان طور که در تصویر مشاهده می کنید یک کوئری جدید با نام csv2 ایجاد می شود. این کوئری یک کپی از کوئری قبلی نیست بلکه یک رفرنس از کوئری قبل است. این بدان معناست که در صورت تغییر در کوئری اول، تغییرات در کوئری دوم نیز ایجاد می شود، در حالی که عمل کپی تغییرات آینده را اعمال نمی کند.

حال نام کوئری دوم را به Students تغییر می دهیم و با استفاده از گزینه Text Filter تنها ردیف هایی که نام آن ها با Student آغاز می شود فیلتر می کنیم. در تصویر زیر مشاهده می کنید که با استفاده از Text Filter و گزینه Begins With، کلمه Student را وارد می کنیم تا تنها فایل هایی که با این کلمه آغاز می شوند باقی بمانند. دلیل استفاده از این راهکار این است که ما می خواهیم تمام فایل هایی که در آینده اضافه می شوند نیز در این فیلتر ها حاضر شوند، لذا با این روش عمل فیلتر را داینامیک می کنیم وگرنه می توانستیم با تیک زدن فایل های مربوط به Student آن ها را فیلتر کنیم اما این نوع فیلتر شامل فایل های آینده نخواهد شد. در واقع اگر در آینده فایلی بام نام Student به این فولدر اضافه شود در این فیلتر نیز ظاهر می شود چرا که این فیلتر داینامیک اعمال شده است.
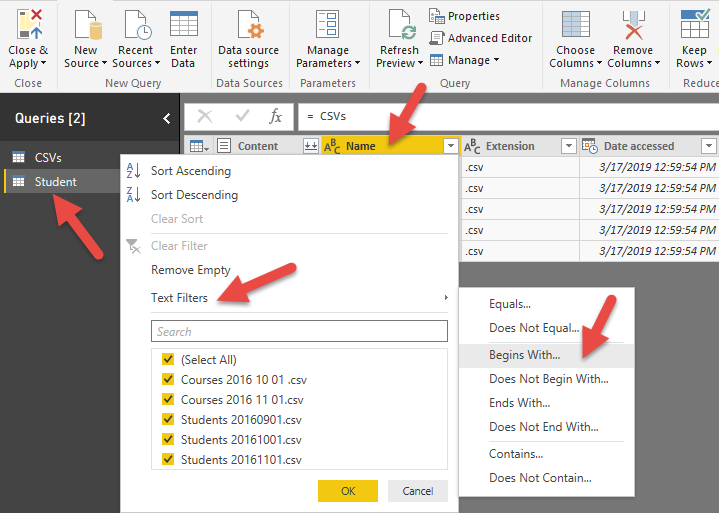
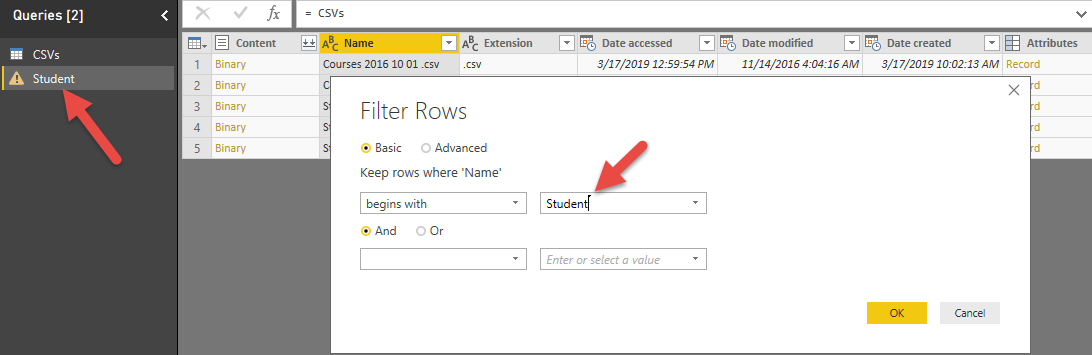
همان طور که در تصویر مشاهده می کنید تنها فایل های Student باقی مانده است.

حال باید عمل Combine را برای فایل های حاوی اطلاعات دانش آموزان انجام دهیم تا تبدیل به یک جدول واحد شود.
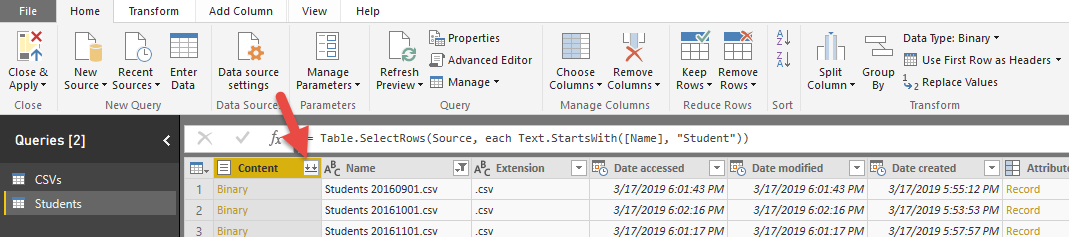
در نهایت فایل ها با یکدیگر تحت یک جدول واحد ادغام می شوند و تمامی مراحل تغییرات داده ذخیره می شود و هر فایل جدید حاوی اطلاعات دانش آموزان به این فولدر اضافه شود، به داده های این جدول نیز اضافه می شود. در ستون Source.Name می توانید مشاهده کنید که داده هر ردیف از کدام فایل واکشی شده است.
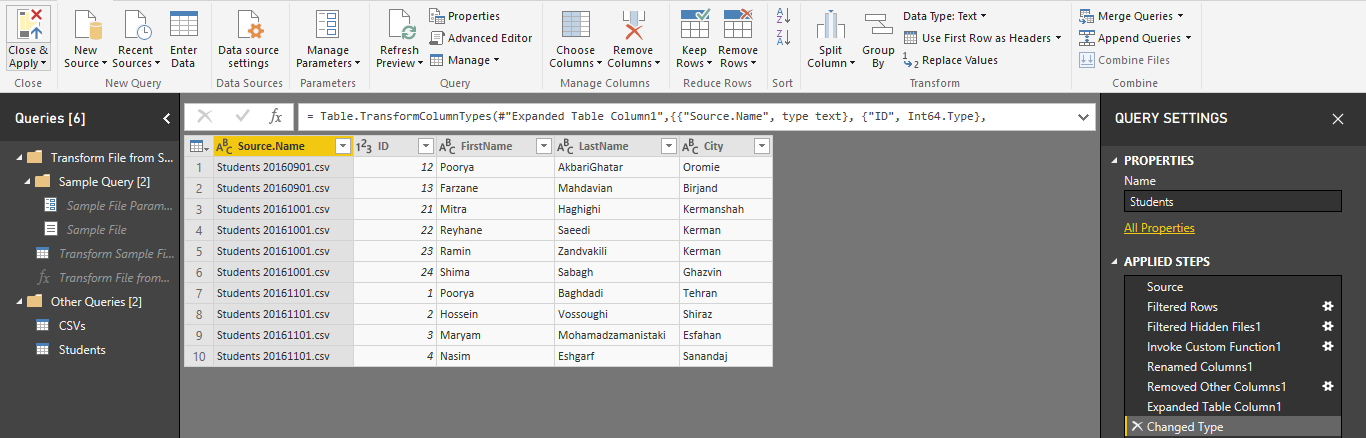
حال یک بار دیگر یک Reference از کوئری ابتدایی که Csvs می باشد ایجاد می کنیم و اعمال ذکر شده برای دانش آموزان را این بار برای دروس نیز تکرار می کنیم. همان طور که در تصویر مشاهده می کنید تنها 2 فایل مربوط به اطلاعات دروس فیلتر شده اند.
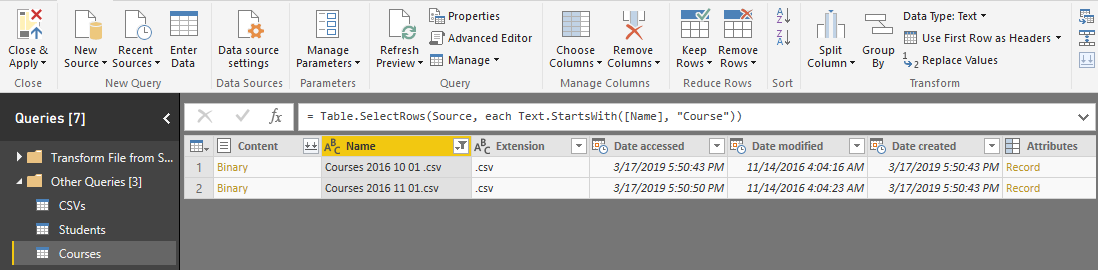
بعد از انجام عمل Combine، فایل نهایی که ادغام 2 فایل دروس است به صورت زیر قابل مشاهده است.
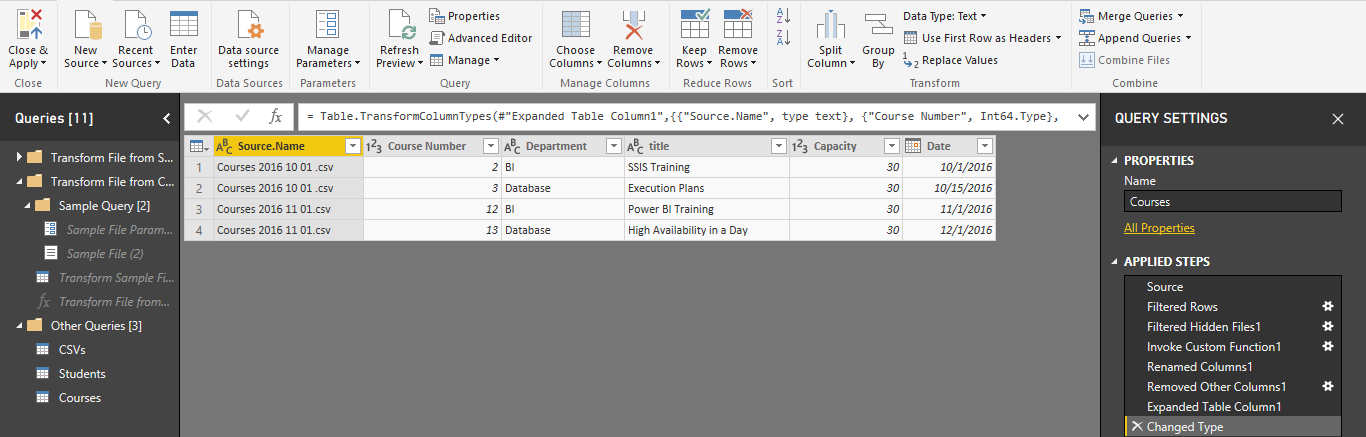
رفتار پیش فرض Power BI
حال بدون هیچ عمل خاصی Close and Apply را مطابق تصویر زیر انتخاب می کنیم.
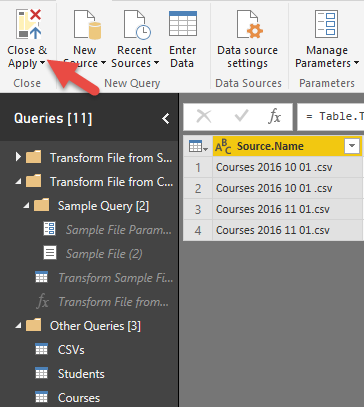
همان طور که در تصویر زیر مشاهده می کنید بعد از Close and Apply، سه جدول در مدل بارگذاری می شود. جدول Csvs، جدول Student و جدول Courses.

جداول Student و Courses جداول مورد نیاز ما در مدل هستند، اما جدول Csvs مورد نیاز ما نیست و تنها به عنوان یک جدول میانی مورد استفاده قرار گرفته است. بارگذاری این جدول میانی در مدل کاربر را گیج می کند که البته این جدول قابل پنهان شدن از چشم کاربر است. برای پنهان کردن این جدول کافی است از قسمت Relationship بر روی جدول کلیک راست کرده و گزینه Hide را انتخاب کنید، اما مشکل اصلی بارگذاری این جدول در RAM است که بدون هیچ دلیلی مصرف RAM را بالا می برد.
بارگذاری این جدول بلا استفاده در RAM باعث افت عملکرد و تحمیل بار اضافه به مدل می شود. در دنیای واقعی جداول ما 5 رکورد یا 10 رکورد نخواهند داشت. برخی از جداول میلیون ها رکورد دارند و اگر بدون دلیل در RAM بارگذاری شوند باعث کاهش بیش از حد عملکرد مدل خواهند شد. بنابراین هر جدول اضافی را از مدل حذف کنید.
بهینه سازی مدل
برای حل مشکل باید به Edit Query برگردیم. بر روی جدول CSVs کلیک راست کنیم. گزینه Enable Load به طور پیش فرض برای تمامی جداول فعال است. برای جلوگیری از Load جداول میانی باید این گزینه را غیر فعال کنیم.
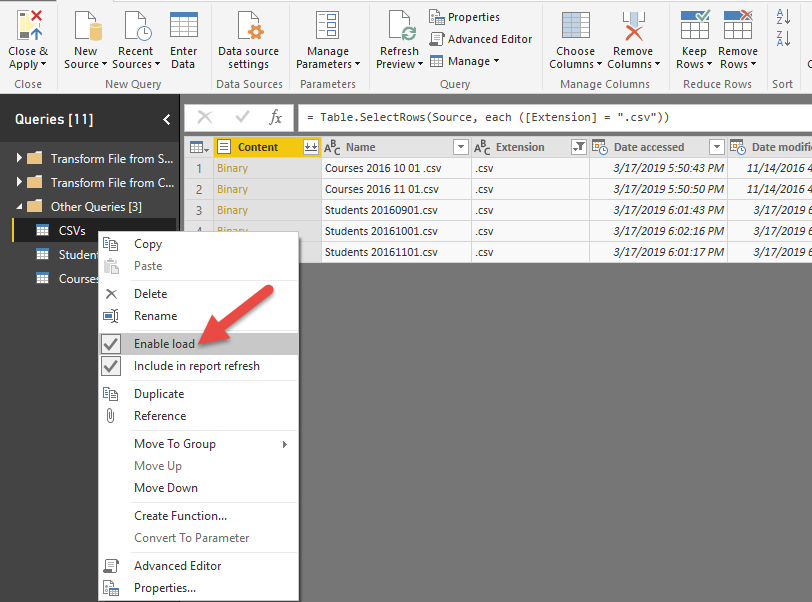
بعد از غیر فعال کردن این گزینه با پیامی مواجه می شویم که به به ما هشدار می دهد، در صورتی که از این جدول در بصری سازی خود استفاده کرده اید، پس از این عمل، از بین می رود. از آنجا که از این جدول تنها برای تبدیل داده و ایجاد دو جدول دیگراستفاده نموده ایم نگرانی بابت این پیغام نخواهیم داشت.
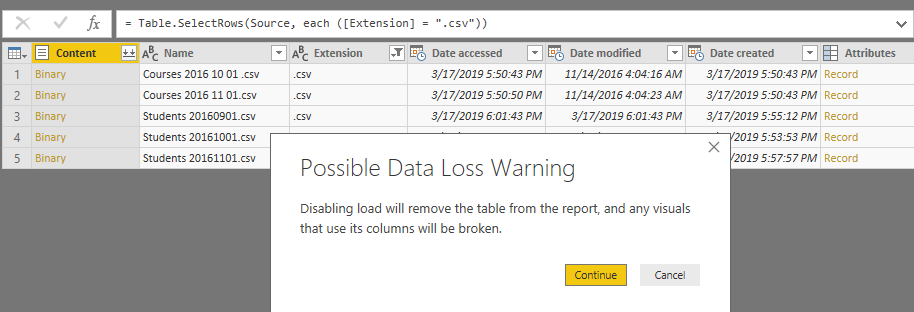
وقتی Continue را انتخاب می کنیم نام جدول به صورت Italic نمایش داده می شود که به ما نشان دهد کدام از جداول در RAM بارگذاری نمی شوند. باید توجه داشت بعد از Refresh این جداول به عنوان جداول میانی در ساخت 2 جدول Student و Courses مشارکت می کنند اما پس از آن در مدل بارگذاری نمی شوند.
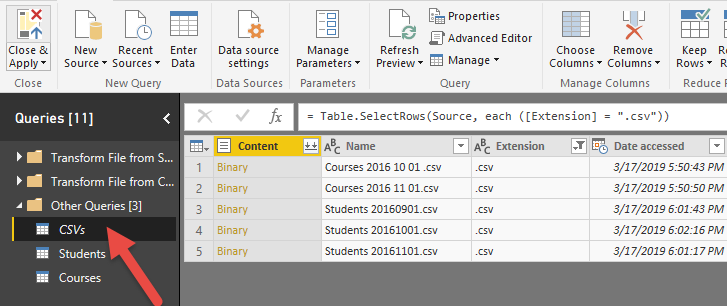
همان طور که در تصویر زیر مشاهده می کنید، دیگر جدول Csvs که تنها به عنوان جدول میانی استفاده شده بود در مدل بارگذاری نمی شود.
جمع بندی
با یک عمل ساده Disable Load برای جداول میانی و کمکی می توان تا حد زیادی عملکرد مدل را افزایش داد و مدل را بهینه نمود. به یاد داشته باشید Query Editor موتور ETL شماست. در واقع این موتور تمام تغییرات، تبدیلات، پاکسازی های مورد نیاز داده را قبل از بارگذاری در مدل اعمال می کند، اما پس از اعمال این موارد داده در مدل و نتیجتا در RAM بارگذاری می شود. به طور پیش فرض همه جداول در مدل و RAM بارگذاری می شود. با جلوگیری از بارگذاری جداول میانی و غیر مفید در RAM می توان تا حد زیادی عملکرد را بهبود بخشید.
مطالب زیر را حتما بخوانید
-

چهارمین مسابقه بزرگ Power BI ایران (طراحی رزومه)
1.15k بازدید
-
تبدیل فایل صورت وضعیت پرتفوی سهام نماد “وسپه” به Power BI
2.18k بازدید
-
نمونه کار پاوربیآی Power BI در زمینه مدیریت مصرف انرژی
746 بازدید
-
نمونه کار تحلیل داده در Power BI با موضوع اقتصاد ایران و جهان، آقای احسان جعفری
740 بازدید
-
نمونه کار پاور بی آی با موضوع اقتصاد ایران و جهان، آقای محمدرضا سلیمی
591 بازدید
-
نمونه پروژه Power BI اقتصاد ایران و جهان، آقای هادی علوی
500 بازدید





ممنون از اموزش مفیدتون.
آیا با حذف یک جدول ک کاربردی دیگر ندارد فضای اشغال شده در RAM خالی می شود؟
در کل بهتره جداولی که کلا نیازی ندارین رو از ابتدا بارگذاری نکنید
ممنون از مطلب مفیدتون..خیلی روی گزارشم موثر بود..بی نهایت تشکر